LAN Troubleshooting Problem Areas
Certification Objectives
- Physical Layer Responsibilities
- Data Link Layer Responsibilities
- Ethernet / IEEE 802.3
- Token Ring / IEEE 802.5
- FDDI
- ATM LAN Emulation (LANE)
- Encapsulation Methods
It’s not much fun first thing on a Monday morning getting swamped with calls from employees, clients, and customers complaining about extremely slow network response times. As a network administrator it is your responsibility to isolate the problem and determine the root cause. Often there are no apparent symptoms other than the bottleneck caused by everyone arriving at work and jumping on board to log in to various systems, retrieving e-mail, and surf the Web.
The emergence of corporate intranets presents significant challenges for LAN administrators and network managers. Traditionally, traffic patterns have been governed by the 80/20 rule (80% of traffic is destined for a local resource, while 20% of traffic requires internetworking). Recently this model has changed to the complete opposite: a 20/80 rule. In today’s environment, technology has elevated the level of business in organizations. Network administrators and managers must keep up with new applications and changing traffic patterns, without overextending allocated network budgets.
This chapter discusses some LAN problems that network administrators face in their everyday battle maintaining and troubleshooting. In the first section we’ll examine the responsibilities of the first two layers of the OSI model. We will also study various LAN technologies, highlighting the characteristics and problems associated with each. Subsequent sections cover ATM LAN Emulation (LANE), discussing its role in a network infrastructure; and methods for encapsulating Protocol Data Units (PDUs) transmitted to receiving station.
The Physical layer provides the necessary mechanical, electrical, functional, and procedural characteristics to initiate, establish, maintain, and deactivate connections for data. This layer is responsible for carrying information from the source system to its destination. One of the main functions of the Physical layer is to carry the signaling to the Data Link layer of the remote system. Repeaters and hubs are Physical layer devices. These devices are not intelligent; in other words, they can only provide electrical signaling on a wire.
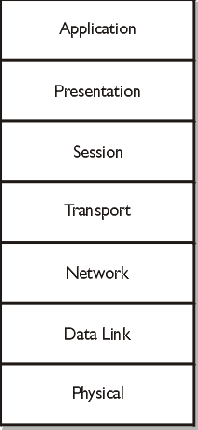
Figure 1: Seven-layer OSI model
At the Data Link layer are the specifications for topology and communication between two end-stations. The Data Link layer connects the physical network functionality (cables, signaling, and digital pulses) with the abstract world of software and data streams. At this layer you will see devices such bridges and switches, both using frame information to control the flow of traffic across the network. In addition, the Data Link layer creates packet headers and checksum trailers, encapsulates datagrams into frames, and does error detection. Hardware addresses are also mapped with IP addresses (commonly know as Address Resolution Protocol ARP) at this layer.
After data is received from the Network layer, the Data Link layer puts data into a frame format. All information received from the upper layers of the OSI model must be put into the data field of the frame (between 46 and 1500 bytes). A frame is added with source and destination MAC addresses, along with data field information, and a CRC trailer is created. At this point, the Data Link layer puts the frame on the network for transmission.
As data is being received on a system, the Data Link layer reads the incoming frame. If the MAC address in the destination field is its own, the Data Link layer must process the incoming information. A CRC check is then performed on the frame, comparing the results to information in the frame trailer. If the information matches, the header and trailer are removed in order to forward the data information to its peer layer (the Network layer). On the other hand, if the information is different, a request is sent to the sending station requesting a retransmission.

Figure 2: Data Link sublayers: LLC and MAC
The Institute of Electrical and Electronics Engineers (IEEE) has subdivided the Data Link layer into two sublayers: Media Access Control (MAC) and Logical Link Control (LLC) as shown in Figure 2-2.
The Media Access Control (MAC) sublayer is the interface between user data and the physical placement and retrieval of data on a network. Generally, the MAC has four major functions:
Physical Layer Responsibilities
The Physical layer is at the bottom of the Open Systems Interconnection (OSI) reference model (Figure 2-1). This conceptual model illustrates the flow of data from one computer software application to another over some type of network medium. There are seven layers, each having a specific function of data communications between two functional computer systems.The Physical layer provides the necessary mechanical, electrical, functional, and procedural characteristics to initiate, establish, maintain, and deactivate connections for data. This layer is responsible for carrying information from the source system to its destination. One of the main functions of the Physical layer is to carry the signaling to the Data Link layer of the remote system. Repeaters and hubs are Physical layer devices. These devices are not intelligent; in other words, they can only provide electrical signaling on a wire.

Figure 1: Seven-layer OSI model
Data Link Layer Responsibilities
The second layer up in the OSI model is the Data Link layer, which is responsible for transmitting data across a physical link with a reasonable level of reliability. For instance, if there are multiple stations utilizing one common path for transmission, there must be some type of control mechanism in place for all stations to share that common path. The Data Link layer may provide this control functionality as well as others, such as synchronization, error control, and flow control, to ensure successful data transmission and reception between remote systems.At the Data Link layer are the specifications for topology and communication between two end-stations. The Data Link layer connects the physical network functionality (cables, signaling, and digital pulses) with the abstract world of software and data streams. At this layer you will see devices such bridges and switches, both using frame information to control the flow of traffic across the network. In addition, the Data Link layer creates packet headers and checksum trailers, encapsulates datagrams into frames, and does error detection. Hardware addresses are also mapped with IP addresses (commonly know as Address Resolution Protocol ARP) at this layer.
After data is received from the Network layer, the Data Link layer puts data into a frame format. All information received from the upper layers of the OSI model must be put into the data field of the frame (between 46 and 1500 bytes). A frame is added with source and destination MAC addresses, along with data field information, and a CRC trailer is created. At this point, the Data Link layer puts the frame on the network for transmission.
As data is being received on a system, the Data Link layer reads the incoming frame. If the MAC address in the destination field is its own, the Data Link layer must process the incoming information. A CRC check is then performed on the frame, comparing the results to information in the frame trailer. If the information matches, the header and trailer are removed in order to forward the data information to its peer layer (the Network layer). On the other hand, if the information is different, a request is sent to the sending station requesting a retransmission.

Figure 2: Data Link sublayers: LLC and MAC
The Institute of Electrical and Electronics Engineers (IEEE) has subdivided the Data Link layer into two sublayers: Media Access Control (MAC) and Logical Link Control (LLC) as shown in Figure 2-2.
MAC Layer
The Media Access Control (MAC) sublayer is the interface between user data and the physical placement and retrieval of data on a network. Generally, the MAC has four major functions:

Logical Link Layer
IEEE standard 802.2 defines the Logical Link Control field (LLC). It is a Data Link control layer that is used by 802.3 and 802.5 and other networks. LLC was originally designed by IBM as a sub-layer in the Token Ring architecture. In essence, this sub-layer generates and interprets commands to control the flow of data, including recovery operations for error detection.The Logical Link layer also provides the connection-less and connection-oriented data transfers. Connection-less data transfers are frequently designated as LLC Type 1, or LLC1. This transfer service does not require data links or link stations to be established. Once a Service Access Point (SAP) has been enabled, the SAP can transmit and receive data from a remote SAP using connectionless service, as well. The connection-oriented portion of data transfers are designated as LLC Type 2, or LLC2. This transfer service requires the establishment of link stations. Once a connection has been established, a mode setting command is required, thus requiring each link station to manage its own link state information.
The LLC protocol is a subset of a High-Level Data-Link Control (HDLC) protocol, a specification presented by the ISO standards body (International Standard Organization). The protocol enables link stations to operate as peers, in that all stations have equal status on the LAN.
LAN administrators supporting NetBIOS and SNA traffic across LAN segments should be familiar with LLC. Most often you will see LLC2 used when SNA traffic is traversing your network. There is also a possibility that you can see it directly encapsulated into Frame Relay. In these instances the router simply forwards LLC2 frames and often implements LLC link-stations. NetBIOS uses LLC to locate resources, and then LLC2 connection-oriented sessions are established.
LLC Type 1 Operation
With the exception of SNA and the multitude of vendors supporting NetBIOS over NetBEUI, Type 1 is the most prevalent class of LLC. LLC1 is generally used by Novell, TCP/IP, OSI, Banyan, Microsoft NT, IBM, Digital, and most other network protocols. No specific subset exists for the operation of LLC1. The information transfer mode is the only form of operation for LLC1.
The application most commonly used with LLC1 is called Subnetwork Access Protocol (SNAP). Typically, LLC1 operation is through this special subsection of the IEEE 802.2 specification. LAN vendors often implement this protocol. The SNAP application was presented to simplify network protocols’ adjustment to the new frame formats introduced by the IEEE 802.2 committee. SNAP is implemented with Novell, Apple, Banyan, TCP/IP, OSI and many other fully stackable protocols that are OSI driven.
The IEEE has defined two fields known as DSAP (Destination Service Address Protocol) and SSAP (Source Service Access Protocol). For the most part, the SAP fields are reserved for protocols which have implemented the IEEE 802.x protocols. One of the reserved SAP fields is designated for non-IEEE protocols. To enable SNAP, the SAP values in both the DSAP and SSAP are set to AA (hexadecimal). The control field is set to 03 (hexadecimal). This will help distinguish the various protocols running.
In LLC Type 1 operation, the DSAP and SSAP are both set to AA, and the control field is set to 03 to indicate unnumbered information packets. The SNAP header in an Ethernet packet has four components:
- The Data Link encapsulation headers (destination and source address, and the CRC trailer)
- The 3-byte 802.2 headers (set to AA, AA, and 03)
- The 5-byte protocol discriminator immediately following the 802.2 header
- The data field of the packet
In networking today, vendors are translating their codes over to the LLC frame format. For example, Novell NetWare previously used a proprietary Ethernet frame. Novell has registered their NetWare operating system with the IEEE and can now use the SAP address of EO in their LLC frames. IEEE 802.x frames are now the standard default for NetWare 3.12 and 4.x implementations.
The decision to choose a connection-oriented network instead of a connection-less network centers on the functionality desired and needed. Using a connection-oriented system can incur substantial overhead; however it does provide data integrity. On the other hand, connection-less operation consumes less overhead but is susceptible to errors. Thus, it may be practical to provide connection-oriented services for a LAN. The application as well as the upper-layer software usually provide for error control for LANs (at the Transport layer). Today, with LAN network protocols handling connection-oriented services, connection-less methods are more prevalent.
LLC Type 2 Operation
Of the two Link Layer Control services, LLC2 is the more complicated. This service provides the functionality needed for reliable data transfer (quite similar to Layer 4 function). LLC2 also allows for error recovery and flow and congestion controls. The protocol supports specific acknowledgments connection establishment, as well as providing for flow control, making sure that the data arrives in the order it was sent. LLC2 service incurs more overhead than LLC1.
The connection-oriented services are used in LAN services today. The protocols that do not invoke a Transport or Network layer (NetBIOS and NetBEUI) are the most common. Microsoft NT, Sun Solarnet, IBM Warp Server, and others use this type of connection. Most LAN protocols do not use this mode of LLC. Most LAN protocols have Network, Transport, and Session layers built into the protocol, and use a connectionless mode of LLC.
Ethernet / IEEE 802.3
Ethernet is the oldest LAN technology commonly used throughout the business industry today, and is still deployed in most traditional LAN infrastructures. This technology conforms to the lower layers (Physical and Data Link) of the OSI model. Ethernet remains an effective LAN technology if implemented and deployed strategically.
The nodes on an Ethernet network implement a simple rule: Listen before speaking. In an Ethernet environment, only one node on the segment is allowed to transmit at any given time, due to the CSMA/CD protocol (Carrier Sense Multiple Access/Collision Detection). Although this manages packet collisions, it increases transmission time in two ways: If two nodes transmit at the same time, the information will eventually collide, which will require each node to stop and re-transmit at a later time (see Figure 2-3).

Figure 3: Sending stations A and D collide
CSMA/CD Protocol
CSMA/CD (Carrier Sense Multiple Access/Collision Detection) is an access technique used in Ethernet that is categorized as a listen-then-send access method. When a station has data to send, it must first listen to determine whether other stations on the network are talking (communicating). Ethernet primarily uses one channel for transmitting data and does not employ a carrier. As a result, Ethernet encodes data using a Manchester code. In Manchester coding, a timing transition occurs in the middle of each bit, and the line codes maintain an equal amount of positive and negative voltage. Many LANs that don’t use a clocking mechanism use either Manchester or Differential Manchester encoding. The timing transition has good-timing signaling for clock recovery from data received. In an Ethernet network, Manchester coding provides the functionality of a carrier signal, since Ethernet does not transmit data by a carrier.
If a channel is busy on an Ethernet network, other stations cannot transmit; they must wait until that channel is idle (meaning that there is no data being transmitted on the network) to contend for transmission. In the Ethernet implementation there is a likelihood that two stations can simultaneously transmit (once the channel is idle). Often this produces what is known as a collision. When a collision is detected, a signal is propagated to other stations sharing that common wire. A random timer is set on each station to prevent other collisions from occurring.
Network administrators should not be alarmed by increased collision rates. Collisions don’t necessarily result in poor Ethernet performance. In many instances, an increasing collision rate indicates that there is more offered load. Ethernet actually uses collisions to distribute shared bandwidth among stations on the network wanting to utilize the channel for transmission. Ethernet uses the collision information to redistribute the instantaneous offered load over the available time, thereby utilizing the channel effectively.
Let’s assume that Station A (Figure 2-3) has the channel occupied, and Stations C and D are contending stations waiting for an idle channel in order to transmit. In this case, Station C is closer to Station A than Station D, and C seizes the channel before Station D because the signal reaches C first. Station C is now ready to transmit, although Station D sees the channel as idle. Station C begins its transmission, and then Station D transmits, resulting in a collision. Here the collision is a direct function of the propagation delay of a signal, and the distance between the contending stations.
Many network administrators believe that CSMA/CD is better utilized in an environment where the cable length is much shorter. This access technique is probably best suited for networks on which intermittent transmissions are prevalent. When there is increased traffic volume on an Ethernet segment, the chances for collision increases because that particular segment is being utilized more frequently.
Collision Detection
Under the Manchester coding, a binary 1 is represented by a high-to-low voltage transition. A binary 0 is represented by a low-to-high voltage transition. This representation helps determine if a carrier sense is present on the network. If the network detects a carrier signal, the station proceeds with monitoring the channel. When existing transmission is done, the monitoring station transmits its data while examining the channel for collisions. In an Ethernet network, transceivers and interface cards can detect collisions by examining and monitoring the voltage level of the signal line that Manchester produces.If a collision is detected during transmission, the station in the process of transmitting will suspend its transmission to initiate a jam pattern. The jam pattern consists of 32–42 bits and is initiated long enough to ensure that other stations on the segment have detected the collision. Once a collision is detected, the transmitting station sets random timers, usually referred to as slot times. In essence, the slot represents 512 bits or a minimum frame size of 64 bytes. An integer n is used to calculate the wait time for a station. Once time n expires, the station can then finish transmitting (retransmission). If during the retransmission a collision is detected, the integer n is doubled and the station must then wait the duration before re-transmitting.
Ethernet’s design causes packet starvation—packets experience latencyy up to 100 times the average, or completely starve out due to 16 collisions. Packet starvation, commonly known as the packet starvation effect (PSE), occurs as a result of the CSMA/CD implementation (the unfairness), as described previously in the CSMA/CD algorithm. The PSE makes CSMA/CD LANs unsuitable for real-time traffic except at offered loads much less than 100%. Many network administrators believe that Ethernet LANs behave poorly at offered loads much higher than 50%. Errors in Ethernet implementation and the inherent unfairness of CSMA/CD has attributed to this belief.
The theory behind PSE is quite simple. In a CSMA/CD implementation, PSE will occur when two stations compete for access under the CSMA/CD algorithm. The probability of one station winning over another for access to the channel is about the same as the ratio of their maximum back-off values. When the network is idle, two stations prepare for transmission. At approximately the same time, the two station attempt to transmit and cause a collision.
When this occurs, they both back off a random amount based on the number of collisions (N) that the packet has been a part of. If N is less than or equal to 10, the back-off is between 0 and 2N1. It is between 0 and 1023 otherwise. The probability that an older packet selects a smaller back-off value than a newer packet with fewer collisions, is less than the ratio of the newer packet’s maximum back-off (2N–1 or 1023) divided by the older packet’s maximum back-off. Because this value increases exponentially, unless a packet comes ready when no other host is ready to send, it will usually either get access to the bus very quickly or it will experience 16 collisions and starve out. Under high loads, there is usually another packet waiting to send, and so long delays and packet starvation occur to a significant percentage of packets.
Late Collisions
A late collision is a collision that is detected only after a station places a complete frame of the network. A late collision is normally caused by an excessive network segment cable length that causes the time for a signal to propagate from one end of a segment to another part of the segment, to be longer than the time required to place a full frame of the network. This small windowing in late collisions may result in two stations attempting to transmit simultaneously without knowledge of each other’s transmissions, causing transmission to collide. This is somewhat similar to two trains traveling on the same rail (due to schedule conflicts) without anyone aware of the error. At some point, the two trains will collide.A late collision is detected by a transmitter usually after the first slot time of 64 bytes, and where frames are in excess of 65 bytes. One thing to remember is that both normal and late collisions occur in exactly the same manner; the late one just happens later than normal. Defective and faulty equipment such as repeaters, connectors, Ethernet transceivers, and controllers can also be the cause of late collisions.
To help alleviate some of the throughput on an Ethernet segment, many network administrators deploy routers as a means for maximizing throughput. For example, a two-port bridge splits a logical network into two physical segments and only lets a transmission cross if its destination lies on the other side. The bridge forwards packets only when necessary, reducing network congestion by isolating traffic to one of the segments. In contrast, routers link multiple logical networks together. These networks are physically distinct and must be viewed as separate collision domains (Figure 2-4). The router performs not only the physical segmentation (each port has a unique network number), but also provides logical segmentation. In Figure 2-5 a router is used to logically segment the network into three distinct segments, thus maximizing the throughput on each network segment.

Figure 4: Collision domain on Ethernet segment

Figure 5: Router segmentation
Ethernet Statistics for Troubleshooting
The following are key statistics and events that are extremely helpful and necessary for proper base-lining and troubleshooting of an Ethernet segment.Frame Sizes for Ethernet Frames
There is a limit to the size of frames an Ethernet segment can transmit.- Minimum Þ 64 bytes
- Maximum Þ 1518 bytes
Frame Check Sequence (FCS)
The frame check sequence (FCS) provides a mechanism for error detection. Each transmitter computes a CRC with the address fields, the type/length field, and the data field. The CRC is then placed in a 4-byte FCS field.Keep in mind that faulty network interface cards (NICs) may also result in FCS errors.
Jabbers
Jabbers are long, continuous frames exceeding 1518 bytes that provide a self-interrupt functionality which prevents all stations on the network from transmitting data. Unlike the CSMA/CD access technique used in Ethernet, where stations must listen before sending data, jabbering completely violates CSMA/CD implementation by prohibiting stations from transmitting data. Be aware of the fact that jabbering may be the result of defective NICs, which may need to be replaced immediately. A jabbering condition can result in poor network performance, ultimately causing workstation and file-server disconnects.Cyclic Redundancy Check (CRC Errors)
In the rule of operation, a CRC check on data fields is initialized before any Ethernet transmissions. The results are appended to the data frame in the FCS field which are 4 bytes in length. A CRC check is also conducted when the destination receives the frame. The CRC check on the data field is then compared to the FCS field. If the results do not match, the frame is discarded and the CRC error count is incremented.Runts
Runts are short frames that are less than 64 bytes long. They are usually the result of collisions. If a runt frame is well formed, however (that is, it has a valid FCS), then it is usually the result of a faulty NIC or its driver.SHOW INTERFACE Command Output
When troubleshooting Ethernet problems, you can use the SHOW INTERFACE ETHERNET command to look at errors, collision rates, and so on. Figure 2-6 illustrates the output from this command in Cisco routers. This command can be found in Cisco’s IOS Software Command Summary reference manual for Release 11.2 and higher.Exam Watch: Remember to track and monitor excessive collision rates. Keep in mind the utilization rate, before collisions present serious problems on the network.

Figure 6: Output from Cisco’s SHOW INTERFACE ETHERNET command
Token Ring / IEEE 802.5
T oken ring is a LAN technology that helps reconcile the problems of contention-based access to a media by granting every station equal access. To accomplish this, the network passes a 3-byte frame commonly know as a token from station to station. When a station wants to transmit, it waits upon the arrival of the token. Essentially, to transmit you need to possess the token (see Figure 2-7). When the token arrives, the station creates a data frame and transmits it onto the wire. The stations then relay the frame around the ring until it reaches its respective destination.
Figure 7: Token-ring passing
One of the major differences between Ethernet and Token Ring is that the Token Ring NICs are intelligent. In other words, Token Ring NICs are able to manage their physical ring, in addition to transmitting and receiving data. NICs are intelligent in the sense that they provide a fault-tolerant solution for Token Ring connected servers. The redundant NIC-enabled drivers switch traffic to a backup NIC if a failure is detected on the active NIC. This keeps your servers connected to the network and reduces downtime.
Understanding MAC Communications
The key to troubleshooting and isolating the inherent problems of Token Ring networks is your ability to understand MAC communications. For that reason, it’s important for network administrators and LAN technicians to analyze, observe, and capture the MAC communications by way of a protocol analyzerConnecting token stations to a shared medium involves wiring stations to a central hub, commonly known as a media access unit (MAU). The MAU may be used to interconnect other MAUs to expand the connectivity. A MAU may also be called a multistation access unit (MSAU). Typically, a MSAU connects up to eight Token Ring stations. When interconnecting MSAUs, be sure that they are oriented in the ring. Otherwise, the Token Ring will have a break and it will not operate properly.
In order for new stations to enter the network, a ring-insertion routine must first be conducted. Initially, the station first conducts a media check to check the existing lobe connections (if any exist). After checking the lobe connections, the station then attaches the ring and searches the ring for an active monitor. If no active monitor is on the ring (18-second lapse time) the station then initiates a claim-token process. Then the station transmits a duplicate address test (DAT) frame, which is checked by each active station to see that the new station address is unique. A flag in the frame is set to indicate an error if the station’s address duplicates an existing station already on the ring. If no errors are detected, the new station continues with the initialization process.
Token Ring frames always travel in one direction, in a downstream motion. Stations relay frames in a logical ring fashion by repeating the frame, bit for bit. This puts a tremendous amount of dependency on the stations waiting to receive signals from their nearest active upstream neighbor (NAUN). These signals are then repeated to downstream neighbors. A station must always know the MAC address of its NAUN in case it receives incorrect data. A neighbor notification, which occurs every seven seconds, allows stations to discover their MAC address.
Upon receiving data frames, an Address Recognized and Frame Copied bit, usually located in the frame status field, is set at the end of the frame. The frame then traverses the ring until the originator receives it. The originator checks the A and C bits to verify the frame was received. The frame is then stripped, and the token is released by the sender in order for the process to reinitialize. If a station receiving the token has no information to send, the token is forwarded to the next station. One bit of the frame, the T bit, is altered if the station possessing the token has information to receive. Unlike Ethernet, in Token Ring the frames proceed sequentially around the Ring. And because a station must claim the token before transmitting, collisions do not occur in a Token Ring infrastructure.
For efficiency in this LAN architecture, a priority mechanism is used. This priority mechanism permits certain user-designated, high-priority stations to use the network more frequently. There are two fields with Token Ring access fields that control the priority mechanism: the priority field and the reservation field. Those stations with a priority equal to or higher than the priority of a token can seize that token. Once the token is seized and changed to an information frame, the stations with priority higher than the transmitting station can possess the token for the next pass around the network. The new generated token will include the highest priority of the station seizing the token.
In our discussion we have used the term frames in many instances to describe the data portion traversing the network ring. To fully understand exactly how this ring topology operates, you need to understand the frame format. In this format you will have access to the setting information, which determines the ring operation. Following are the fields in the frame format:
- Starting Delimiter (SD) Indicates start of frame
- Access Control (AC) Priority settings
- Frame Control (FC) Indicates frame type
- Destination Address (DA) Specifies the address of destined station
- Source Address (SA) Specifies the address of originating frame
- Optional Routing Information Contains user data (LLC) or control information (MAC frame information)
- Frame Check Sequence (FCS) CRC-32 error check on FC, DA, SA, and information fields
- Ending Delimiter (ED) Indicates end of data or token frame
- Frame Status (FS) Contains A and C bits indicating frame status
- Initiate the neighbor notification process
- Monitor the neighbor notification process
- Ensure data frames do not continually traverse the rings
- Detect lost tokens and data frames
- Purge the ring
- Maintain the master clock
- Ensure ring delay
Ring error monitoring is another important and effective management tool. The purpose of the ring-error monitor is to receive soft errors or beacons—MAC frames—that are transmitted from any Token Ring station. A MAC address table is maintained for those stations transmitting errors, as well as active counts and error types. LAN administrators can use protocol analyzers to respond to the ring-error monitor functional address. This will capture beacon and soft-error MAC frames, as well as insert them into a beaconing ring.
A ring purge is a normal method of resetting communications on a Token Ring network. This mechanism provides a means for issuing a new token. Ring purges are normal events and are typically encountered during ring insertion and ring de-insertion; however, as with Ethernet collisions, high amounts of ring purges will cause network performance degradation.
When the active monitor enters the ring-purge process, the purge timer starts and the active monitor transmits a ring purge MAC frame. The transmission occurs without waiting for a free token and without releasing a free token upon completion. Continuous idles (0) are sent by the adapters. After the frame has traversed the ring, the active monitor receives the transmission and checks for transmission errors. Such errors could be code violation errors or check sequences (CRC) errors.
Any error detection triggers transmission of ring-purge MAC frames until a frame is received with no transmission errors or until the expiration of the ring-purge timer. This timer’s function is to limit the number of retransmission of ring-purge MAC frames during this process. Once the ring-purge MAC frame has traversed the ring error-free, the active monitor sets a one-second timer. After an error-free frame is received, the adapter transmits a free token of a priority equal to the reservation priority in the last ring-purge MAC frame that was stripped by the adapter.
Troubleshooting Token Ring Networks
When troubleshooting Token Ring problems, you can use the SHOW INTERFACE TOKEN RING command to look at errors, collision rates, and so on. Figure 2-8 illustrates the output from the SHOW INTERFACE TOKEN RING command in Cisco routers. This command can be found in Cisco’s IOS Software Command Summary reference manual for Release 11.2 and higher.
Figure 8: Output from SHOW INTERFACE TOKEN RING command
Being able to understand the ring processes is critical for effectively troubleshooting Token Ring networks. Many LAN administrators overlook such key processes. A good rule of thumb when troubleshooting is to try not to oversimplify the problem-resolution process. The obvious is not always the best indicator; a thorough approach is more realistic for isolating LAN performance problems.
Following are the most common ring processes:
- Ring Inserting A five-phase process that every station must go through to insert into the ring
- Token Claiming The process by which standby monitors contend and elect a new active monitor.
- Neighbor Notification The process by which a station notifies a downstream neighbor of its MAC address.
- Beaconing The process stations utilize in an attempt to remove bad segments.
- Ring Purge Instructs all NICs to reset. This process is an attempt to recover from a break in the Token Ring. Ring purges are normal reactions to the simple soft errors that occur when stations enter or leave the ring.
- Protocol Timers There are 14 timers on every Token Ring NIC. Each timer performs its own function.
- Aborts If a station regularly reports that it is aborting transmissions, that station is usually in error. Transmission are aborted when errors are detected—errors internal to a station, or a token in which the third byte is not an ending delimiter.
- Beacon If a beacon alert appears, chances are your ring is inoperable. This situation demands immediate attention. Some protocol analyzers will indicate the beaconing station. Usually the fault occurs between the beaconing station and its upstream neighbor.
- Beacon Recovery An event is logged in the system when the ring recovers from a beacon event.
- Claim Token The presence of claim frames on the ring means that the ring is going through the monitoring-contention process. You can determine what station initiated monitor contention by analyzing the events that precede the claim tokens.
- Duplicate Mac Address This event occurs when a Token Ring station that is trying to enter the ring has the same MAC address as an existing station on the ring.
FDDI
FDDI became a popular LAN networking technology because of its ability to reach 100 Mbps throughput. Today other technologies have closed the gap by providing the demanded throughput. Nevertheless, FDDI still provides network stability and fault tolerance. FDDI supports both a ring and star topology. FDDI’s Ring implementation is quite similar to IBM’s legacy Token Ring, although FDDI implementation provides more redundancy with a second ring. The second ring is generally used when a failure has occurred on the primary ring.FDDI transmission is comparable to Token Ring transmission in the sense that a token passes around the ring from station to station. When a station needs to transmit, it must first posses the token. The frame traverses the ring until it is received by its intended destination node. The receiving station copies the frame and continues to forward it along the ring, setting the Frame Copied Indicator (FCI) bit. The transmission is completed when the originating station receives the frame and checks the FCI to make it has been properly set. The frame is then removed from the ring, and the next station wishing to transmit can seize the token for transmission, repeating this process.
This communications implementation is much more effective than Ethernet, for the simple reason that larger frames (4096 bytes) are supported. Many network administrators view token passing as less cumbersome than the CSMA/CD access method of communicating. Token passing tends to perform more effectively and efficiently as higher utilization levels are reached.
Attachments to FDDI rings are typically designated as either dual attachment stations (DAS) or single attachment stations (SAS), depending on whether they are attached to both rings or only one ring. Dual attachment stations have the ability to loop back to the secondary ring, if the primary fails. In the FDDI implementation, the DASs are attached to both, whereas SASs have only a single physical-medium dependent (PMD) connection to the primary ring by way of a dual-attached concentrator (DAC). The DAC provides the necessary connection between multiple networks and the FDDI ring. One way to think of this architectural implementation is to compare it to a highway with access ramps for multiple secondary roads. In the proper implementation, the end-user nodes are rarely connected directly to a FDDI backbone, due to the high costs involved and the fact that end-user nodes seldom need maximum speed at the desktop.
Token possession governs the data flow in the FDDI implementation. However, stations attach new tokens to the ends of their transmissions, and a downstream station is allowed to add its frame to the existing frame. Consequently, at any given time, several information frames can traverse the ring. Unlike Token Ring implementation, all stations monitor the ring for invalid conditions such as lost tokens, persistent data frames, or a break in the ring. Beacon frames are cascaded throughout the FDDI network (identifying failures within the domain) if a node has determined that no tokens have been received from its NAUN during a predetermined time period.
Whenever a station receives its own beacon from an upstream station, it automatically assumes that the ring has been repaired. If beaconing exceeds its timer, DASs on both sides of the failure domain loop the primary ring with the secondary ring in order to maintain full network redundancy.
From the Classroom
Pointers for Effective Troubleshooting and Network Analysis
- Baseline your network to determine normal operation. When problems occur, it’s difficult to determine the state of your network under extreme conditions. LAN administrators must know how their network performs when it’s healthy.
- Approach the problem systematically. Apply problem-solving techniques to the situation and try to eliminate the obvious. It’s like working a multiple-choice math problem.
- Analyze and evaluate symptoms.
- Isolate the problem area with thorough network analysis.
- Develop test strategies and apply them to problem areas.
- Record and document repairs.
Exam Watch: Baselining your network is critical in determining the problematic areas. Baselining also serves as very helpful network analysis for problem isolation and resolution.
—Kevin Greene, Network Engineer
ATM LAN Emulation (LANE)
Although this topic isn’t required for the CIT exam, it is pertinent to the CCIE exam and is beneficial to the reader to have it introduced here.Many corporations have invested substantial funds in traditional LAN infrastructures. It isn’t always feasible for a corporation to reengineer or abandon its current infrastructure, however, a viable solution may be to make subtle changes either at the backbone or on local segments. Whatever the case, a strategic approach is the optimal plan of action. Network administrators must be mindful of the fact that technology is only as good as the plan that drives its design and implementation.
In the traditional and legacy environments, networks were designed with a general assumption that broadcasting to all hosts on a particular LAN was an easy task. Depending on your point of view, you may argue that this is true, given the fact that hosts reside on a shared communications medium. However, Asynchronous Transfer Mode (ATM) approaches networking from a different angle than the traditional legacy LAN. ATM is a widespread technology that carries considerable legacy LAN traffic, or traffic originated by TCP/IP software. But ATM networks are connection-oriented.
ATM was developed around 1983 by AT&T Bell Labs, but it took roughly 10 years before an official forum was created to mature this technology into a working network infrastructure. ATM has the ability to provide high data rates and quality of service within an exiting LAN or WAN infrastructure. The ATM Forum's LAN Emulation (LANE) specification defines a mechanism that allows ATM networks to coexist with legacy LANs. Unlike Ethernet and token-based topologies, ATM does not vary its frame size. ATM uses a fixed packet size or cell of 48 bytes for all data communications. This fixed packet size enables a more predictable traffic rate than networks with variable-length packets. ATM can accurately manage, predict, and control bandwidth utilization by regulating the number of packets transmitted.
ATM technology will inevitably play a central role in the evolution of telecommunication and computer data communication. It is widely perceived to be the underlying technology for high-speed networks of the future, such as ISDN. Its advantage over the existing networks is obvious. ATM has high access speed from 1.5 Mbps to 1.2 Gbps. ATM can provide effective throughput for multimedia applications: video, scientific visualization, multimedia conference, distance learning, and so on.
Many network administrators are realizing that there are great difficulties in replacing the existing network totally with ATM. The technological challenge and economical burden make it almost impossible to implement ATM without the support of established networks. The dilemma for ATM developers is how to integrate existing networks with ATM. Currently, professionals are trying to investigate the technologies of extending the existing network applications to work over ATM.
LAN Emulation (LANE) allows bridging and routing of this traffic over an ATM network. In essence, LANE is a technique used to emulate a shared communication medium similar to Layer 2 LANs, between ATM attached clients (LECs); see Figure 2-9. Today’s bridging methods allow these services to support interconnection between ATM networks and the traditional LANs. This implementation supports interoperability between software applications residing on ATM-attached end-nodes and the traditional LAN end nodes. Different types of emulation can be defined, ranging from emulating the MAC service (such as IEEE 802.x LANs) up to emulating the services of OSI Layers 3 and 4.
One of the main purposes of LAN Emulation service is to help provide existing applications with an interface to the ATM network via protocol stacks like APPN, IP, IPX, and AppleTalk—as if they are running over the traditional legacy broadcast networks. These upper protocols use a MAC driver for communications; therefore, it is essential for LANE services to use a MAC driver in order to provide access to the ATM network.
In today’s current implementation of traditional LANs, stations are able to transmit data without an existing connection. LAN Emulation provides the appearance of a connectionless service to the participating end-nodes so that the state of existing applications remains the same. Hence, LAN Emulation conceals the ATM network from the users. Thus it presents the assumption that the legacy Ethernet and Token Ring are the existing LAN technology. How does this work? Simply by making the ATM network emulate a MAC network, permitting all endpoints to transparently transmit MAC-based packets to each other.
Emulated LANs are somewhat comparable to physical LANs in the sense that both provide communication of data frames among their users. However, users are not able to communicate directly across emulated LAN boundaries, because each emulated LAN is independent of the others. Each emulated LAN comprises a set of LAN Emulation Clients (LECs) and a single LAN Emulation Service (LE Service). The LAN Emulation Services consist of the LAN Emulation Configuration Server (LECS), the LAN Emulation Server (LES), and the Broadcast and Unknown Server (BUS). Each LEC is part of an ATM end node and represents a set of users, identified by MAC addresses.

Communication among LECs, and between LECs and the LE Service, is performed across ATM virtual channel connections (VCCs). Each LEC must communicate with the LE Service across control and data VCCs. Emulated LANs can in fact operate in numerous environments, such as Switched Virtual Circuit (SVC), Permanent Virtual Circuit (PVC), or both. SVC enables the network to allocate bandwidth on demand from the end-users’ service requests. PVCs are virtual channels defined at the users’ end-points and along the route that has been predefined for connection.
Following are descriptions of the LAN Emulation components:
- LAN Emulation Client (LEC) Provides data forwarding, address resolution, and other control functions. Provides either a MAC-level emulated Ethernet IEEE 802.3 or IEEE 802.5 service interface. A LEC can be a LAN Switch, router, Windows 95 client with ATM card and drivers, UNIX host, or file servers.
- LAN Emulation Server (LES) Control-coordination function for emulated LAN. Provides the registering and resolves conflicts with MAC addresses. All queries are sent to the LES to resolve MAC address conflicts. Queries are forwarded directly to clients, or the LES responds directly to queries.
- Broadcast and Unknown Server (BUS) Manages the data sent between LEC and broadcast MAC address; all multicast traffic; and initial unicast frames sent by the LAN Emulation Client before the data-direct target ATM address has been resolved. One BUS is allowed for each Emulated LAN, and each LES can only have one BUS associated with it.
- LAN Emulation Configuration Server (LECS) Comprises the configuration information for all Emulated LANs in the administrative domains. Designates each LEC to an emulated LAN by providing the LEC the LES ATM address.
LEC data frames are sent to the BUS, which in turn serializes the data frames and retransmits them to the attached LECs. In an SVC environment, the BUS is active in the LE Address Resolution Protocol to enable a LEC to locate the BUS. The BUS then becomes the manager of ATM connections and distribution groups. The BUS must always exist in the Emulated LAN, and all LECs must join its distribution group via multicast forward VCC.
In order for clients to map LAN destinations with the ATM address of another client or BUS, an address resolution procedure must manage and resolve any conflicts. Clients use address resolution to set up data-direct VCCs to carry frames. An LE_ARP frame request is forwarded to the LE Service over a control point-to-point VCC for all frame transmissions whose LAN destination is unknown to the client. The LES may then perform one of the following procedures:
- Use a control-distribute VCC or one or more control-direct VCCs to forward the LE_ARP frame to respective client. Once a response is received and acknowledged by the client, it is then forwarded over the control VCCs to the originator.
- Issue an LE_ARP reply for the client that has registered the requested LAN destination with the LES. A LAN destination is sent to the client once a request has been acknowledged.
Encapsulation Methods
Data encapsulation is an extremely important process in peer-to-peer communications—essentially, the process by which layer protocols exchange information among peer layers. In this communications model, there is a sending station and a receiving station that exchange what is known as protocol data units (PDUs). PDUs must either move down or move up the OSI protocol stack, depending on which stations are sending and receiving. The sending station PDUs travel down the protocol stack from the upper-layer protocols. Once the information reaches the receiving station, each lower-level protocol receives the PDUs and passes them up the stack to the protocol’s peer layer.Each layer within the protocol stack depends on its peer service function (as you know, each layer provides some functionality). In order for upper layers to provide services to lower-layer peers, data must be encapsulated as headers and trailers are added to data. In Figure 2-10 there are two stations, A (sending) and B (receiving). As Station A sends data to Station B, the encapsulation process is working behind the scenes at each layer, transparent to users (see Figure 2-11). For instance, as data approaches the network layer from the upper-layer protocols of Station A, the Network layer encapsulates data received from the Transport layer with its network header. The network header contains source and destination addresses necessary for moving data through the network.

The Data Link layer receives and then will encapsulate the Network layer information into a frame for Data Link services, by appending a frame header and frame trailer. Generally, physical addresses can be found in frames (Ethernet and Token Ring). Finally, the Physical layer will encode the Data Link frame in 1s and 0s (100011111) for transmission on the wire to Station B. Station B will receive the frame and work it to its upper-layer protocols. Before information can be passed along to upper-layer peers, however, headers and trailers must be stripped off, completing the decapsulation process.


Certification Summary
The CCIE examination details various troubleshooting scenarios. This chapter covers significant issues in problematic areas for troubleshooting LAN problems. It is important to thoroughly investigate network performance; make sure you’re tracking errors, application throughput, collision rates, peak utilization periods, and any other statistical analysis information to assist in troubleshooting. A good rule of thumb for LAN troubleshooting is to approach each problem individually with a standardized procedure for effectively isolating and resolving network problems. It’s almost impossible for anyone to effectively troubleshoot LAN problems without an intimate knowledge of the existing LAN technologies and infrastructures (Ethernet, Token Ring, and FDDI). A key to the examination is knowing what to look for by understanding symptoms, characteristics, and functionality of the communications protocols stack (Physical, Network, and Data Link layers).In preparation for the CIT examination, you should focus on understanding the behavioral aspects of Ethernet, Token Ring, and FDDI in terms of providing a medium for connected stations to communicate. Hands-on troubleshooting is crucial; for example, you’ll want to capture packets on the network with sniffers and protocol analyzers for in-depth data analysis. You should understand Cisco’s debug commands, show commands, and other help commands (traceroute, ping, netstat, etc.) for troubleshooting. Know what each command does; during the exam, these commands could be vital in problem isolation and resolution.
Finally, practice makes perfect. It’s almost impossible to know the specifics of the exam, so you’ll need to know a substantial amount of everything from A to Z. Also, you must be able to pinpoint a problem and know how to break it down from the general to the specific. For instance, you might need to track a slow-response problem to the point where you can see that a particular channel is being overutilized, resulting in the slow response. Try to get as much game-time experience as possible; it’s difficult going into the game without any pre-game warm-ups. Take a few snaps on the side and prepare yourself mentally for the challenge. Stay focused and rely on your knowledge of the mechanics to help you overcome the emerging unknowns. Good luck!
Two-Minute Drill
- The Physical layer provides the necessary mechanical, electrical, functional, and procedural characteristics to initiate, establish, maintain, and deactivate connections for data.
- The second layer up in the OSI model is the Data Link layer, which is responsible for transmitting data across a physical link with a reasonable level of reliability.
- At the Data Link layer are the specifications for topology and communication between two end-stations.
- The Media Access Control (MAC) sublayer is the interface between user data and the physical placement and retrieval of data on a network.
- The Logical Link Control field (LLC) is a Data Link control layer that is used by 802.3 and 802.5 and other networks.
- Type 1 is the most prevalent class of LLC. LLC1 is generally used by Novell, TCP/IP, OSI, Banyan, Microsoft NT, IBM, Digital, and most other network protocols.
- The LLC2 service provides the functionality needed for reliable data transfer (quite similar to Layer 4 function).
- Ethernet conforms to the lower layers (Physical and Data Link) of the OSI model.
- In an Ethernet environment, only one node on the segment is allowed to transmit at any given time, due to the CSMA/CD protocol (Carrier Sense Multiple Access/Collision Detection).
- CSMA/CD (Carrier Sense Multiple Access/Collision Detection) is an access technique used in Ethernet that is categorized as a listen-then-send access method.
- In the Ethernet implementation there is a likelihood that two stations can simultaneously transmit (once the channel is idle), this is known as a collision.
- There is a limit to the size of frames an Ethernet segment can transmit.
- The frame check sequence (FCS) provides a mechanism for error detection.
- Jabbers are long, continuous frames exceeding 1518 bytes that provide a self-interrupt functionality which prevents all stations on the network from transmitting data.
- In the rule of operation, a CRC check on data fields is initialized before any Ethernet transmissions.
- Runts are short frames that are less than 64 bytes long. They are usually the result of collisions.
- When troubleshooting Ethernet problems, you can use the SHOW INTERFACE ETHERNET command to look at errors, collision rates, and so on.
- Remember to track and monitor excessive collision rates. Keep in mind the utilization rate, before collisions present serious problems on the network.
- Token ring is a LAN technology that helps reconcile the problems of contention-based access to a media by granting every station equal access.
- One of the major differences between Ethernet and Token Ring is that the Token Ring NICs are intelligent. Token Ring NICs are able to manage their physical ring, in addition to transmitting and receiving data.
- It’s important for network administrators and LAN technicians to analyze, observe, and capture the MAC communications by way of a protocol analyzer.
- When troubleshooting Token Ring problems, you can use the SHOW INTERFACE TOKEN RING command to look at errors, collision rates, and so on.
- FDDI became a popular LAN networking technology because of its ability to reach 100 Mbps throughput.
- FDDI transmission is comparable to Token Ring transmission in the sense that a token passes around the ring from station to station.
- Data encapsulation is an extremely important process in peer-to-peer communications—essentially, the process by which layer protocols exchange information among peer layers.